Hey guys, how are you?
In this post, I’ll talk about my preferred tips and tricks that I use in ODI (any version). I’m always using these pieces of code for pretty much everything I do in ODI especially because it makes the code more elegant, dynamic, and easier to change later.
First, let’s talk about my all-time preferred, Loops. Normally we learn to loop in ODI using a count variable and a check variable. In our case, one variable is used to get the number of applications to be looped and another variable is used to identify that application number and transform it into the application name itself. The flow should be something like this:
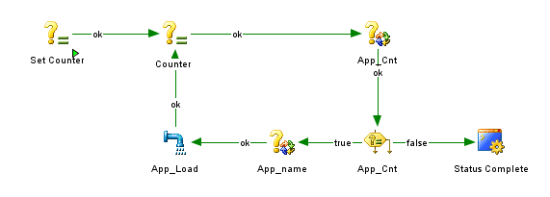
We set a variable with the initial value, enter in the loop and increase the variable. The App_Cnt variable uses the value of the incremental variable. The number of applications and their names is inserted inside a parameter table. The same variable checks if we need to loop more. The App_Name variable uses the App_Cnt value to take the proper App name. Then we load the data into Hyperion Planning, putting the #APP_NAME variable into the KM APPLICATION option (created in the last post), making the application name dynamic. This leads to a lot of work and variables to maintain.
There’s an easier way to do the same thing using ODI procedures. In ODI procedures we have the source and target tabs concept. Basically, the command in the target tab will be executed for each row that returns from the query in the source tab. Also, we can pass the information that returns in the source tab query to the target tab command. That means we can simplify the above loop just by doing this:
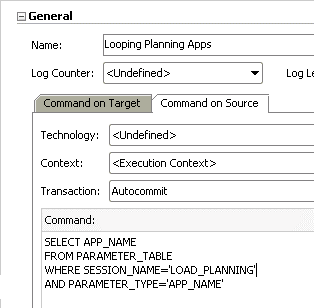
In the command on the source tab, we only need to create a query that will return all apps that we want to loop. The application name will be returned in the APP_NAME column.
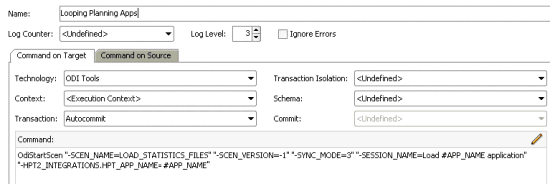
For the target tab, we need a little more work, but it is also easy. First, we need to create an ODI package containing the ODI interface used to load into Hyperion Planning. Then in the target tab, we need to set it as “ODI Tools” technology and write an OdiStartScen command to call the interface package passing the name of the application (#APP_NAME from the source tab) as an input parameter. This procedure will call the interface scenario for each row that results from the source tab query. This will allow us to pass one application name at a time to the scenario, creating the same effect as the previous loop but in a much simpler way to maintain.
This method works for every kind of looping in ODI, especially with Hyperion Planning in multiple application environments. In the next post, we’ll take a deeper look at how we can use this together with the planning repository metadata to create dynamic interface loads.
This is a very powerful way to do pretty much everything in ODI, even build the target query dynamically querying the ALL_TAB_COLUMNS or DB commands like manage the partitions by querying the ALL_TAB_PARTITION/SUBPARTITION.
I always like to say that ODI is way more than just an ETL tool and that people need to start to think about ODI as being a full development platform, where you may create any kind of code that you wish there. Today I’ll describe how we may create a simple (but dynamic) merge statement between two similar tables using an ODI procedure that will read from ALL_CONSTRAINTS, ALL_CONS_COLUMNS, and ALL_TAB_COLS Oracle tables to figure out what to do.
Let’s imagine this scenario: we have several stage tables that are truncated and loaded every day with daily records from a source system. We have another set of tables that are used to store all the historical information and the process uses the first stage tables as sources, merging its data against the historical tables using their primary key. This is very common in a lot of places where we have a stage data layer that stores daily data pulls and then a “base” data layer that stores the historical data. In this scenario that we will describe here, both source and target set of tables have very similar structures, with the same column names, data types, and so on.
Using the conventional ODI development process, we would need to create one mapping object for each set of source->target tables, so if we have 50 sources that need to be merged against 50 targets, we would need to create 50 ODI mappings. Since the set of source->target tables are similar in this case, we may be smarter and create an ODI process that will receive a table name as an input parameter (in this case the target table name) and it will create a merge statement against those two tables in a dynamic way using Oracle metadata dictionary.
For those that are not familiar with Oracle metadata dictionary, it's nothing more than a set of tables that exists in the Oracle database that contains information about its existing components like, information about its tables, what are the columns that they have, which is their data type and so on. This is a great resource place that ODI may read from it and build generic code using its results. Let’s see how it looks like with a real example.
Imagine that you have two tables with the following structure:
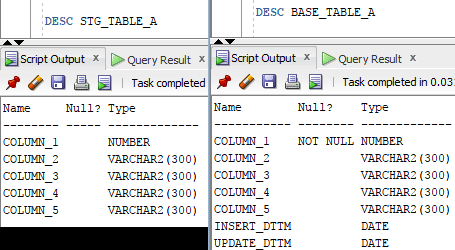
As you can see, our base table is almost the same as our stage table and the only difference is that it contains 2 additional columns named INSERT_DTTM and UPDATE_DTTM that will be used as “control columns” to identify when that data was inserted/updated in our base table. For ODI to figure out which columns are presented in which table, we may query ALL_TAB_COLS in Oracle filtering its table name, as below:
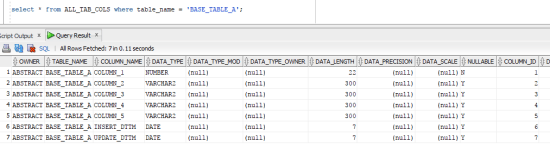
This is showing us all the table columns that this table contains. Similarly, if we query ALL_CONSTRAINTS and ALL_CONS_COLUMNS, we may get all the table constraints (like Primary Key) with all its associated columns:
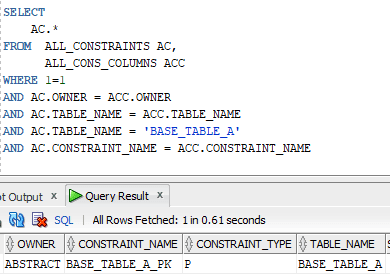
With those two sets of data, we may create a SQL that will build our dynamic merge statement. To make it easier, I’ll show you the final SQL statement now, which is divided into two pieces, and then I’ll explain each of them:
WITH
TABLE_PARAMS AS
(
SELECT 'BASE_TABLE_A' AS TABLE_NAME,
'SCHEMA_A' AS TABLE_OWNER
FROM DUAL
),
TABLE_PK AS
(
SELECT ACC.OWNER,
ACC.TABLE_NAME,
ACC.COLUMN_NAME
FROM ALL_CONSTRAINTS AC,
ALL_CONS_COLUMNS ACC,
TABLE_PARAMS
WHERE 1=1
AND AC.OWNER = ACC.OWNER
AND AC.TABLE_NAME = ACC.TABLE_NAME
AND AC.OWNER = TABLE_PARAMS.TABLE_OWNER
AND AC.TABLE_NAME = TABLE_PARAMS.TABLE_NAME
AND AC.CONSTRAINT_NAME = ACC.CONSTRAINT_NAME
AND AC.CONSTRAINT_TYPE = 'P'
),
MAIN_TAB_COLS AS
(
SELECT ATC.OWNER,
ATC.TABLE_NAME,
ATC.COLUMN_NAME
FROM ALL_TAB_COLS ATC,
TABLE_PARAMS
WHERE 1=1
AND ATC.TABLE_NAME = TABLE_PARAMS.TABLE_NAME
AND ATC.OWNER = TABLE_PARAMS.TABLE_OWNER
AND ATC.COLUMN_NAME NOT IN ('INSERT_DTTM','UPDATE_DTTM')
AND ATC.COLUMN_NAME NOT IN (SELECT COLUMN_NAME FROM TABLE_PK)
)
SELECT MTC.TABLE_NAME AS TARGET_TABLE,
REPLACE(MTC.TABLE_NAME,'BASE_','STG_') AS SOURCE_TABLE,
PK_ST_LIST,
PK_S_LIST||','||(LISTAGG('S.'||MTC.COLUMN_NAME ,',') WITHIN GROUP (ORDER BY MTC.COLUMN_NAME)) || ',SYSDATE,SYSDATE' AS TABLE_S,
PK_T_LIST||','||(LISTAGG('T.'||MTC.COLUMN_NAME ,',') WITHIN GROUP (ORDER BY MTC.COLUMN_NAME)) || ',T.INSERT_DTTM,T.UPDATE_DTTM' AS TABLE_T,
LISTAGG ('T.'||MTC.COLUMN_NAME||'=S.'||MTC.COLUMN_NAME , ',') WITHIN GROUP (ORDER BY MTC.COLUMN_NAME ) AS ST_COLS
FROM MAIN_TAB_COLS MTC,
(
SELECT TP.OWNER,
TP.TABLE_NAME,
LISTAGG ('T.'||TP.COLUMN_NAME||'=S.'||TP.COLUMN_NAME , ' AND ') WITHIN GROUP (ORDER BY TP.COLUMN_NAME ) PK_ST_LIST,
LISTAGG ('S.'||TP.COLUMN_NAME, ',') WITHIN GROUP (ORDER BY TP.COLUMN_NAME ) PK_S_LIST,
LISTAGG ('T.'||TP.COLUMN_NAME, ',') WITHIN GROUP (ORDER BY TP.COLUMN_NAME ) PK_T_LIST
FROM TABLE_PK TP
GROUP BY
TP.OWNER,
TP.TABLE_NAME
) TP
WHERE 1=1
AND MTC.OWNER = TP.OWNER
AND MTC.TABLE_NAME = TP.TABLE_NAME
GROUP BY
MTC.OWNER,
MTC.TABLE_NAME,
PK_ST_LIST,
PK_S_LIST,
PK_T_LIST
The first piece of the SQL contains a WITH clause with three sections:
The second piece is the main one where we will use the three sub-selects from the WITH section to build what we need. In this case, it will return the following columns:
When we run the SQL for our tables in this example, this is the result:

Now we have all information that we need to create a dynamic merge statement for any set of similar tables, but how do we use it in ODI? This is very simple with one of the best features that ODI has (if you read our blog, you know that we just love it): command on source/target. Let’s create a procedure and add our SQL statement in the command on the source tab:
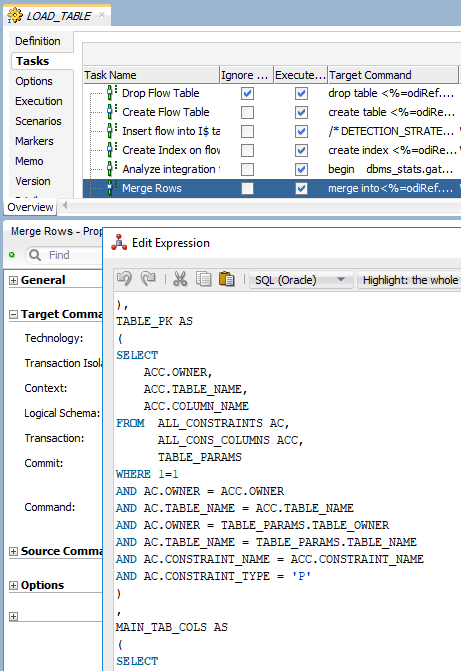
In our command on the target tab, we will add the following code there:
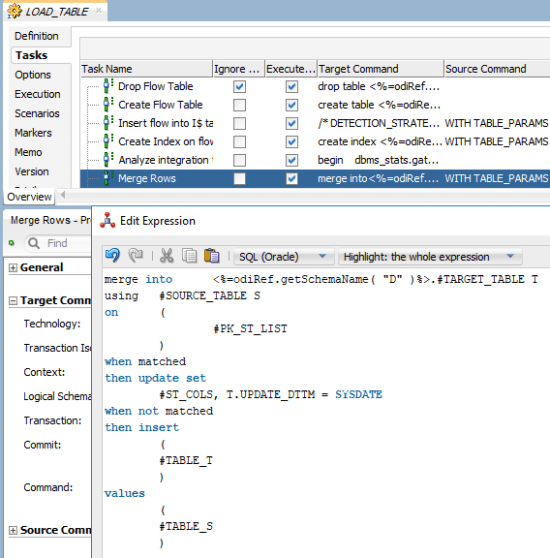
As you can see, this SQL contains a lot of variables. These variables will be used at runtime to receive the return values from the SQL in command on the source. In this way, we don’t need to worry about creating 50 mappings to do 50 merge processes. Instead, we have one procedure that will receive a table name as a parameter and will build the necessary SQL accordingly. Let’s see how it looks like in an ODI package:
As you can see, it’s a very simple package that is receiving a table name as a parameter and then building/running a dynamic merge SQL. This package can be called by an external package that may run it N times with different table names (like doing 50 table mergers with one single procedure). Of course, that this was just one example of a simple merge task, but it shows you the main idea of having ODI building the code for you. You may add more tasks to your procedure to create temp tables, run gather statistics, and so on. There are almost no limits on what you may do using this kind of technique.

