Intelligent Document Processing (or IDP) is the missing link towards implementing end-to-end automation, especially in paper-based work environments. Paper still forms a part of business operations and wherever paper is involved, latency and error due to human handling does creep in. OCR does enable businesses to ingest data into the digital workflow. However, one should remember that while using OCR, the quality of the scanned documents has to be good in order to ingest data in a highly accurate manner. As the popular adage goes, “Garbage In; Garbage Out”. OCR processing is very much similar. Intelligent Document Processing goes much beyond. It allows the user to perform pre-processing steps to improve the image quality and post-processing to improve the data quality and accuracy.
How does Intelligent Document Processing enable business operations?
In a multi-vendor scenario, businesses receive invoices from different vendors in different formats. Similarly, other documents, such as contracts, statements of work, purchase orders and other such lengthy documents, don’t have any particular structure and vary from vendor to vendor.
Intelligent Document Processing helps here. It uses a template-free approach based on the in-built artificial intelligence/machine learning algorithms. It classifies the documents into various categories, extracts the relevant information, and validates it so that it can be processed further.
The output is highly accurate and it is directly integrated into the downstream systems including different applications, ERP systems, workflows, DMS systems, etc. To improve the accuracy levels, the tool comes with in-built pre-processing and post-processing features.
Pre-processing features improve the OCR issues such as lack of clarity, carbon smudges, skewness, noise, contrast, etc. Post-processing features resolve issues such as 5/S, 1/l, 8/B, m/rn, etc. Together they enhance the accuracy levels and throughput of Intelligent Document Processing by manifolds.
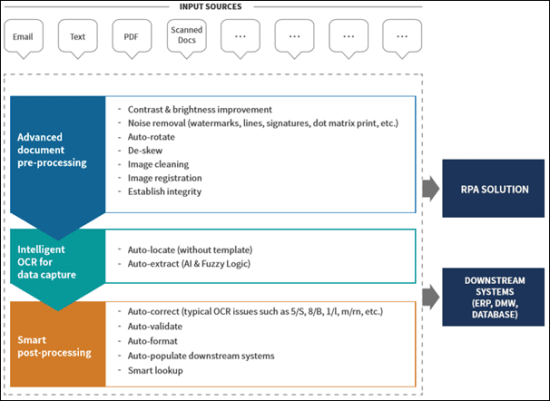
Prominent pre-processing and post-processing features
The most important pre-processing functions include deskewing, sub-imaging or separating an area out from the main image before processing, line removal, image resizing, and inverse text correction or white to black colored text correction. It also includes noise removal, capture lens focusing or alignment for precision capturing, smoothening character edges, intelligent cropping, color correction, image cleaning, image correction, character correction, page bursting into multiple sub-sections, image mirroring, page recognition, etc.
The post-processing functions are required to improve the data capture accuracy from the enhanced image. It includes auto-location of data in an image without the reference of a template, auto-extraction of data, auto-correction of the captured data, auto-validation, auto-formatting, etc. All these features together make the intelligent data capture much more formidable and acceptable as compared to only OCR.
Astounding business benefits brought forth by Intelligent Document Processing
Reading text from PDF images of hard copies allows businesses to undertake more complex use cases, by the day, for automation. Some of these include mobile onboarding, video KYC, claims processing, patient onboarding, identity verification at transit points, summarizing lengthy documents, etc.
Intelligent Document Processing also allows to process all documents types including paper-based ones, classify documents into predefined categories, extract information from unstructured documents, index the documents, and convert the document to a format, which is ready for further processing. It allows converting unstructured data to structured data, which can be easily integrated with downstream systems including enterprise applications, databases, etc. It improves speed and productivity by manifolds even in a paper-driven environment.
Simply put
Intelligent Document Processing is the missing link towards achieving end-to-end automation where paper is still used for different processes. Pre-processing and post-processing feature tremendously improve the accuracy of ingesting the data from unstructured documents. It enhances the throughput and productivity and takes it to the next level allowing the traditional businesses to compete with their digital-born counterparts.

